
La minería de datos es un área que se especializa en identificar y encontrar patrones, correlaciones y anomalías a partir de un conjunto de datos, a los cuales se les aplica diferentes técnicas de análisis, para posteriormente predecir resultados y variables. Dependiendo de lo que se quiera lograr, se deben aplicar ciertos algoritmos que permitan el correcto análisis de los datos. De igual modo, se deben aplicar otras funciones especiales para visualizar y evaluar el contenido que se esta analizando.
A continuación se relaciona una grafica de los campos relacionados con la minería de datos:
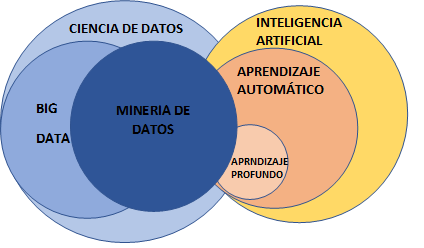
Estos conocimientos son aplicables de una u otra manera en todas las áreas del conocimiento, por ejemplo, ha sido ampliamente usada en la política, por ejemplo, cuando Donald Trump utilizo el Big Data para su campaña electoral al contratar una empresa como Cambridge Analytica para que le ayudaran a analizar a la población, sus intereses e intenciones de votación, a partir de los datos de sus redes sociales, y así enviar publicidad para promocionar su campaña electoral; también ha sido usada para fines publicitarios, industriales, educativos, de negocio, así como también en el área de la salud.
Por ejemplo, a nivel de negocio, a partir de la minería de datos se puede utilizar la información obtenida del análisis para incrementar los ingresos, recortar costos, mejorar sus relaciones con clientes, reducir riesgos y facilitar la toma de decisiones.
En el área de la salud puede ayudar a determinar causas de determinadas patologías o a identificar poblaciones de riesgo, y así ayudar en la detección precoz de enfermedades, de hecho, hubo una investigación enfocada en identificar y predecir aquellos pacientes que podrían padecer alzhéimer al analizar dos grupos de personas, el primero presentaba un deterioro cognitivo más acelerado, mientras que el otro no (stimulus, 2017). Sin embargo, para llevar a cabo esta minería se necesitaron los datos acumulados durante 5 años de 562 pacientes, es decir, que para llevar a cabo una minería exitosa se necesita una gran cantidad de datos, dado que es importante tener una base de datos balanceada y que permita que los algoritmos se apliquen y obtengan resultados fiables y consistentes.
Es importante tener en cuenta que la minería de datos esta directamente relacionada con el aprendizaje automático o inteligencia artificial, ya que este proceso consiste en la creación de modelos que aprendan por si mismos para predecir comportamiento o variables de acuerdo con el tipo de análisis que se este efectuando. Estos modelos de aprendizaje son versiones y pruebas de la aplicación de distintas funciones o ajustes del aprendizaje automático para que la minería de datos resulte exitosa.
Hay que tener en cuenta que existen dos tipos de aprendizaje automático el supervisado y no supervisado. El aprendizaje supervisado consiste en un conjunto de datos (base de datos) entrenados que son etiquetados con una característica para distinguir su clase, por ejemplo, para la tarea de detección de spam en correos electrónicos, se le proporciona una etiqueta como es spam/no es spam. Es decir, este tipo de aprendizaje describe un escenario en que la experiencia contiene información significativa, y a partir de esa etiqueta, el modelo podrá usar la experiencia para ganar experticia, y clasificar un nuevo set de datos que no contenga dicha etiqueta (Shalev-Shwartz y Ben-David, 2014).
El aprendizaje automático no supervisado se caracteriza porque el enfoque del modelo de aprendizaje es distinto ya que los datos no están etiquetados, es decir que no hay una diferencia entre datos entrenados (etiquetados) y los que no. Tomando el mismo ejemplo del spam en los correos electrónicos, en este caso, la tarea sería identificar anomalías en los correos electrónicos para predecir un posible spam (Shalev-Shwartz y Ben-David, 2014).
En este orden de ideas, de acuerdo al tipo de aprendizaje automático que se esté desarrollando es que se deben aplicar los algoritmos para realizar el análisis. Por ejemplo, si el aprendizaje es supervisado se deben utilizar algoritmos como la regresión logística, K- Vecinos más cercanos, Bayas ingenuas, entre otros. Mientras que, para el aprendizaje no supervisado pueden ser de utilidad algoritmos como las redes neuronales.
Cada uno de estos algoritmos funciona de modo distinto para analizar el conjunto de datos, por eso es importante probar su desempeño y evaluarlo a medida que se vaya proponiendo un modelo de aprendizaje.
Finalmente, la minería de datos se puede desarrollar en distintos softwares, esto depende de su nivel de complejidad, dado que algunos exigen conocimientos en programación. Existen herramientas como Python, R, RapidMiner, o herramientas como IBM SPSS u Orange que no necesariamente exigen conocimientos de lenguajes de programación.
Referencias:
Shalev-Shwartz y Ben-David. (2014). Understanding Machine Learning: From Theory to algoritms. Cambridge University Press.
Stimulus. (2017). La minería de datos aplicada a la salud. Recuperado de https://stimuluspro.com/blog/la-mineria-de-datos-aplicada-a-la-salud/
Autora: Paula Navarro Alvarado
Revisión John Gutiérrez Garzón